::: tip
如果没有特别说明,文中的组件都是指函数组件。
:::
基础概念#
1. 应该如何看待函数式组件,他与类组件有什么区别?#
函数式组件与类组件是完全不用的心智模型 (mental model)。
函数式组件是纯函数,它们只是接受 props 并返回一个 React 元素。
类组件是一个类,它们有自己的状态,生命周期,以及实例方法。
在实践中,我们应该将函数式组件视作纯函数,而类组件视作类。忘记声明周期那一套思维,千万不要用各种操作在函数组件里模拟生命周期。
一个纯函数是没有副作用的,而我们的应用必须要有副作用才有意义。因此 React 提供了 useEffect 来处理副作用。
2. 为什么组件会重复渲染?#
这是 React 的一个特性,它会在每次 props 或 state 变化时重新渲染组件。以此来保证组件的状态与视图保持一致。
我们举一个官网的例子:
组件是厨师, react 是服务员。
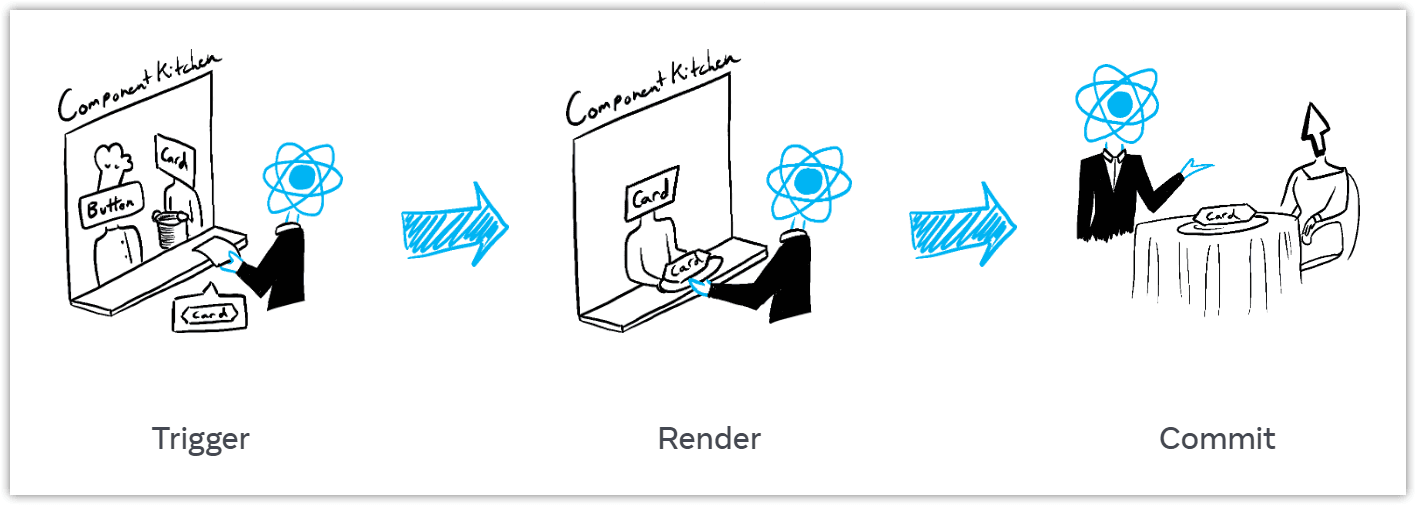
- Triggering a render (delivering the guest’s order to the kitchen)
- Rendering the component (preparing the order in the kitchen)
- Committing to the DOM (placing the order on the table)
当 props 或 state 变化时,React 会触发重新渲染,也就是重新执行函数。
在最终的 Commit 阶段,React 会依据函数的执行结果尽可能的复用 DOM 节点,以此来提高性能。
所以在 React 中,rerender 并不是一个 bug,而是一个特性。也不需要担心性能问题,React 会自动优化。
建议配合官网文档以及这篇文章一起看: Why React Re-Renders
如果还有疑问,建议再看几遍参考资料:
- Render and Commit
- Why React Re-Renders
- 每隔一段时间再读总有收获
3. State 是什么,为什么需要它,为什么有时候它的值与预期总是不一致?#
组件需要响应用户的操作,而用户的操作会导致组件的状态发生变化。因此我们需要一个地方来存储组件的状态,这就是 state。
当 state 发生变化时,React 会重新渲染组件。 这就是 State 的运行机制。
同时这也是为什么 state 的值与预期不一致的原因,因为每一次的重新渲染都是一次函数执行,在每次函数执行中,state 都有不同的值。所有这些渲染中,state 都是独立的,互不影响。
下面是一个例子:
const Counter = () => {
const [count, setCount] = useState(0)
const onClick = () => {
setInterval(() => {
setCount(count + 1)
}, 1000)
}
return (
<div>
<p>Count: {count}</p>
<button onClick={onClick}>Click me</button>
</div>
)
}
点击按钮后,每隔一秒,计数器的值会增加 1。但是我们会发现,计数器的值会一直停留在 1。
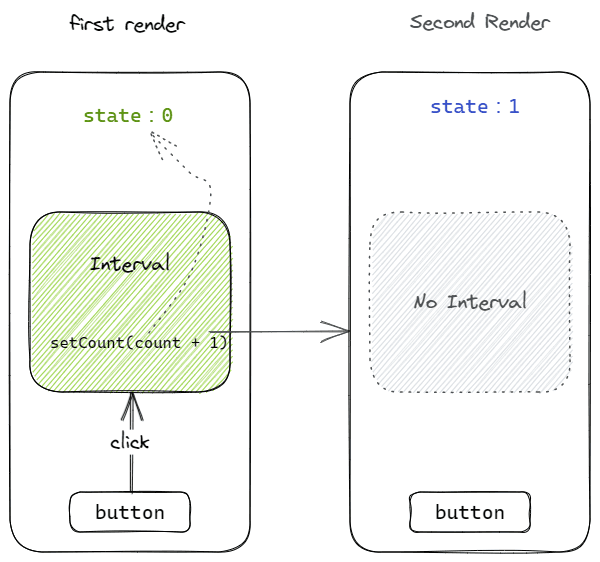
我们可以看到,定时器只在第一次渲染函数的运行时里,而这里的 state 是 0,所以每一次定时器执行取到的 state 都是 0,那么页面上的值就会一直是 0 + 1 = 1。
我们可以将 state 理解为函数状态快照,每次渲染都会有一份新快照,而这些快照是互不影响的。
4. useMemo 是什么,我需要使用它吗?#
useMemo 是一个 Hook,它可以用来缓存函数的返回值。
所以它唯一的用途就是提高性能,因为它可以避免重复计算。
因此,我们必须确保即使当去掉 useMemo 后,组件的行为也不会发生变化。
但是我们应该明确过早的优化是万恶之源,所以在没有性能问题的情况下,我们不应该使用 useMemo。
这句话说的比较模糊,究竟什么时候才是合适的时机呢?
答案是在绝大多数情况下,我们都不需要使用 useMemo。
依据官方文档的说法, 我们可以使用如下代码测试一个计算的耗时:
console.time('filter array');
const visibleTodos = filterTodos(todos, tab);
console.timeEnd('filter array');
// filter array: 0.15ms
当我们的计算耗时大于 1ms 时,我们就可以考虑使用 useMemo 来缓存计算结果了。
另外:useMemo 并不能优化第一次渲染的性能,它只能帮助我们在组件更新时避免重复计算。
既然 useMemo 可以优化性能,那么为什么不在每个地方都使用呢?
有三个原因:
useMemo本身是有开销的,它会在每次渲染时都执行,去比对依赖项是否发生变化,这个计算开销有可能比我们要缓存的计算开销还要大。(尤其还需要考虑数组、对象这种引用类型的依赖)useMemo会使组件的行为变得不可预测,这会导致 bug 的产生。useMemo会使组件的代码变得难以理解,这会导致维护成本的增加。
我们之前说过,React 通过重复执行函数来实现组件的更新,而 useMemo 会跳过某些函数的执行,这就会导致组件的行为变得不可预测。维护者需要去理解这些跳过的函数,这会增加维护成本。
5. useCallback 是什么,我需要使用它吗?#
useCallback 和 useMemo 的作用是一样的,都是用来缓存一些计算结果,但是它们的使用场景不同。
useCallback 用来缓存函数,而 useMemo 用来缓存值。
当一个函数或一个值作为组件的 props 传递给子组件时,如果这个函数或值没有发生变化,那么子组件就不会重新渲染。
所以很多人会使用 useCallback 来缓存函数,用 useMemo 来缓存值。
const TodoList = ({ todos, onClick }) => {
return (
<ul>
{/** ... */}
</ul>
)
}
const App = () => {
const todos = useMemo(() => filterTodos(todos, tab), [todos, tab])
const onClick = useCallback(() => {
// ...
}, [])
return (
<TodoList todos={todos} onClick={onClick} />
)
}
如上边的例子,我们可以看到,我们使用了 useMemo 来缓存 todos,使用了 useCallback 来缓存 onClick。有些人会认为这优化了性能,因为我们避免了子组件的重新渲染。
但实际上这并没有优化性能,因为只有当子组件是 memo 组件时,才会避免子组件的重新渲染。
const TodoList = React.memo(({ todos, onClick }) => {
return (
<ul>
{/** ... */}
</ul>
)
})
6. useEffect 是什么,它有什么用?#
useEffect 是一个 Hook,它可以用来处理副作用。
默认情况下它在每次组件渲染后执行,但可以接收一个依赖项数组,只有当依赖项发生变化时,才去执行。
useEffect的设计目标并不是在函数组件中提供类似于生命周期的功能,而是用来处理副作用,也就是让组件的状态与外部世界同步。
我们看一个官网的例子:
const ChatRoom = ({ roomId }) => {
useEffect(() => {
const connection = createConnection(roomId) // 创建连接
connection.connect()
return () => {
connection.disconnect() // 断开连接
}
}, [roomId])
}
// roomId 默认值 'general'
// 第一次操作 'general' 变为 'travel'
// 第二次操作 'travel' 变为 'music'
如果我们从组件的角度出发,它的行为是这样的:
- 组件第一次渲染时,触发 useEffect,连接到 'general' 房间
- roomId 变为 'travel',组件重新渲染,触发 useEffect,断开 'general' 房间的连接,连接到 'travel' 房间
- roomId 变为 'music',组件重新渲染,触发 useEffect,断开 'travel' 房间的连接,连接到 'music' 房间
- 组件卸载时,触发 useEffect,断开 'music' 房间的连接
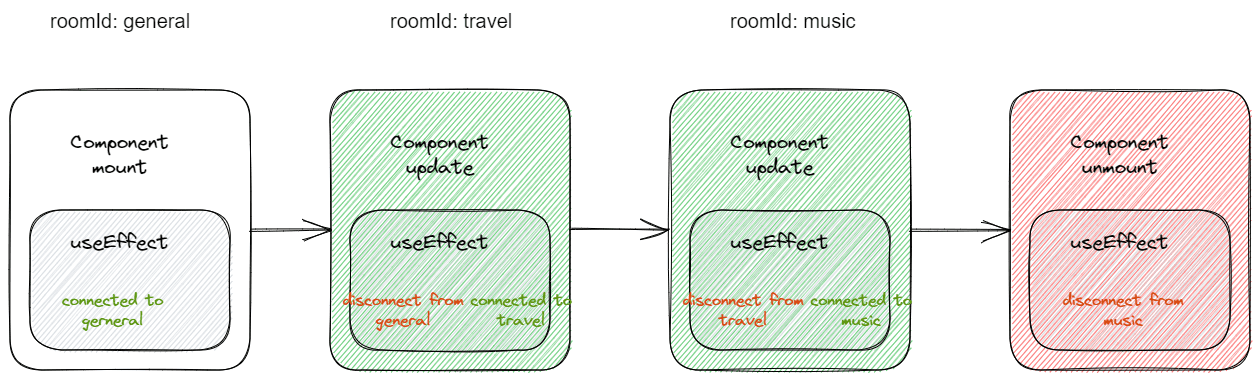
看起来很完美,但是如果我们从 useEffect 的角度出发,它的行为是这样的:
- Effect 连接到 'general' 房间,直到断开连接
- Effect 连接到 'travel' 房间,直到断开连接
- Effect 连接到 'music' 房间,直到断开连接
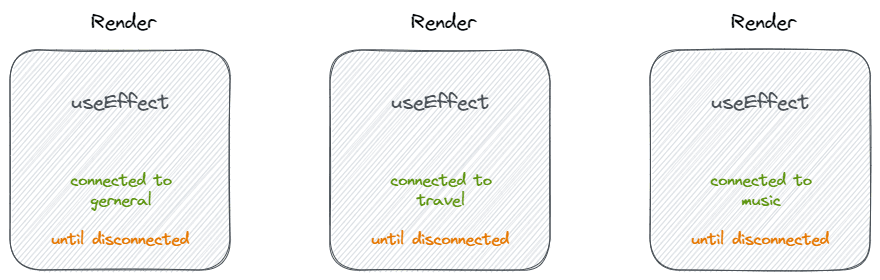
当我们从组件的角度来看待 useEffect 时,useEffect 就变成了一种在组件渲染完成后或者卸载前执行的一种回调函数、生命周期。
而从 useEffect 的角度出发,我们只关心应用如何开始或终止与外部世界的同步。就像写组件的 rendering 代码一样,接收 state,返回 js。我们不会考虑 rendering 代码在 mount、update、unmount 时会发生什么。我们只关注单次的渲染它应该是什么样的。
最后,我们来看有这样一种说法:
The question is not "when does this effect run" the question is "with which state does this effect synchronize with"
useEffect(fn) // all state
useEffect(fn, []) // no state
useEffect(fn, [these, states])
Tweet not found
The embedded tweet could not be found…
重要的不是 useEffect 什么时候执行,而是同步了哪些状态。
状态管理#
1. 什么是状态管理,为什么它在 React 应用中很重要?#
状态管理是指在一个应用程序中追踪、更新和维护数据(状态)的过程。在 React 应用中,状态管理尤为重要,因为它直接影响到应用的用户界面和交互。当状态发生变化时,React 会自动更新相关的组件以反映这些更改。
在 React 应用中,状态管理的重要性主要体现在以下几个方面:
- 可预测性:良好的状态管理可以使应用的行为更加可预测,开发人员可以更容易地追踪和理解状态变化的来源。
- 可维护性:通过组织和管理状态,可以使代码更易于维护,降低应用程序复杂性。这有助于团队在项目中更高效地协作。
- 可扩展性:当应用程序变得越来越复杂,状态管理可以帮助开发人员更好地组织代码和逻辑,从而提高应用程序的可扩展性。
- 性能优化:有效地管理状态可以减少不必要的组件重新渲染,从而提高应用程序的性能。
在 React 中,有多种状态管理方法,例如使用组件内部状态(如 useState Hook)、上下文(Context)API 以及第三方状态管理库(如 Redux、MobX 或 jotai 等)。
2. 如何在函数式组件中使用 useState Hook 管理状态?#
useState 是 React 提供的一个内置 Hook,它允许在函数式组件中添加和更新状态。
在函数式组件内部,调用 useState 函数,并传递初始状态值作为参数。useState 会返回一个包含两个元素的数组:当前状态值和一个用于更新状态的函数。通常,我们使用数组解构赋值来获取这两个值。
const [state, setState] = useState(initialState);
以下是一个简单的示例
import React, { useState } from 'react';
const Counter = () => {
// 使用 useState Hook 初始化计数器状态
const [count, setCount] = useState(0);
// 定义一个函数,用于增加计数器的值
const increment = () => {
setCount(_count => _count + 1);
};
return (
<div>
<p>Current count: {count}</p>
<button onClick={increment}>Increment</button>
</div>
);
}
export default Counter;
在这个示例中,我们创建了一个简单的计数器组件。我们使用 useState Hook 来存储计数器的当前值,并定义了一个 increment 函数来更新计数器。当用户点击 "Increment" 按钮时,计数器的值将递增。
useState 是一个非常实用的 Hook,但在使用过程中可能会遇到一些易出错的点。以下是一些需要注意的问题:
- 不要在条件语句中使用 useState:React 依赖于 Hook 调用的顺序一致来确保正确关联和管理状态和副作用,因此,请确保每次渲染时都以相同的顺序调用 Hook。不要在循环、条件语句或嵌套函数中调用 Hook。
// 错误示范
if (condition) {
const [state, setState] = useState(initialState);
}
- 异步更新:
setState函数是异步的。这意味着当你调用setState时,状态更新可能不会立即生效。如果你需要根据当前状态计算新状态,请使用setState函数的函数式更新形式。
// 正确示范
const increment = () => {
setCount((prevCount) => prevCount + 1);
};
- 在更新时合并状态:与类组件中的
setState不同,函数式组件中的useState在更新状态时不会自动合并对象。如果你的状态是一个对象,请确保在更新时手动合并状态。
const [state, setState] = useState({ key1: 'value1', key2: 'value2' });
// 错误示范
setState({ key1: 'new-value1' }); // 这会导致 key2 丢失
// 正确示范
setState((prevState) => ({ ...prevState, key1: 'new-value1' }));
- 初始化时避免重复计算:如果你的初始状态需要通过复杂计算或副作用函数来获取,可以将初始状态计算函数传递给
useState,以避免在每次渲染时都进行计算。
const [state, setState] = useState(() => computeExpensiveInitialState());
- 初始值只会在组件首次渲染时使用:之后的重新渲染将保持和使用已经设置的状态值,而不会重新应用 initialState。
因此,在使用 useState 时,需要确保正确理解这一行为。如果你需要根据属性(props)或其他外部变量来设置状态的初始值,请确保在状态更新逻辑中正确处理这些依赖关系。
第一种方案是使用 key 属性来触发组件的重新渲染,只需在使用组件时将 key 属性设置为一个唯一值。当需要根据属性(如initialCount)重新渲染组件时,可以将 key 设置为该属性值:
import React from 'react';
import MyComponent from './MyComponent';
function ParentComponent() {
const [initialCount, setInitialCount] = useState(0)
return <MyComponent key={initialCount} initialCount={initialCount} />;
}
export default ParentComponent;
在这个示例中,当 initialCount 属性发生变化时,MyComponent 组件将使用新的 key 值进行重新渲染。这将导致组件根据新的 initialCount 值进行初始化和挂载。
第二种方案是使用 useEffect Hook 来处理外部变量的变化,从而根据需要更新组件状态。
import React, { useState, useEffect } from 'react';
function MyComponent({ initialCount }) {
const [count, setCount] = useState(initialCount);
useEffect(() => {
// 当 initialCount 属性值发生变化时,更新组件状态
setCount(initialCount);
}, [initialCount]);
}
export default MyComponent;
使用 key 方案优点是心智负担小,组件的状态更清晰可预测,缺点是由于 key 的变更会导致整个组件的卸载和挂在,可能会带来较高的性能开销。
使用 useEffect 方案的优点是仅在属性值发生变化时触发重新渲染,而不需要卸载和挂载整个组件。性能开销更低。缺点是需要手动管理可能存在的副作用的清除和重新应用,需要更多的代码来处理属性值的变化和状态更新,组件的状态更加复杂。
根据具体需求和性能要求,可以在这两种方案之间进行权衡。就我个人来说,性能是不需要过早考虑的问题,相反代码的可维护性,状态的可预测性可能对项目质量的影响更大,所以在大部分的场景下我会优先推荐 key 的方案。
3. 什么是上下文(Context)API,它如何解决状态共享问题?#
上下文(Context)API 是 React 中一种用于在组件树中共享状态的方法,无需显式地通过属性(props)逐层传递。它允许你在组件树的某个层级设置一个值,然后在较低层级的任何组件中直接访问该值。这在管理跨越多个层级的共享状态时非常有用,避免了逐层传递属性的繁琐。
要使用 Context API,需要执行以下步骤:
- 创建一个上下文对象:使用
React.createContext函数创建一个新的上下文对象。此函数接受一个默认值作为参数,该值将在未找到匹配的上下文提供者(Provider)时使用。
const MyContext = React.createContext(defaultValue);
- 添加上下文提供者(Provider):在组件树中的适当位置添加上下文提供者。提供者接受一个 value 属性,该属性将作为上下文值传递给消费者(Consumer)。
<MyContext.Provider value={/* shared value */}>
{/* children components */}
</MyContext.Provider>
- 在子组件中使用上下文:在组件树的任何较低层级中,可以使用
useContextHook 或上下文消费者(Consumer)组件来访问上下文值。
// 使用 useContext Hook
import React, { useContext } from 'react';
function MyComponent() {
const contextValue = useContext(MyContext);
// ...
}
// 使用 Context.Consumer 组件
import React from 'react';
function MyComponent() {
return (
<MyContext.Consumer>
{contextValue => {
// ...
}}
</MyContext.Consumer>
);
}
通过使用 Context API,你可以在组件树的任何位置轻松共享状态,无需逐层传递属性。这使得跨多个层级的组件之间的状态共享变得更加简洁和高效。然而,需要注意的是,过度使用上下文可能导致组件之间的耦合过于紧密,从而降低代码的可维护性。因此,在使用 Context API 时,请确保在确实需要全局状态共享的场景中使用它。
4. 什么是 jotai 库,它如何帮助管理应用程序的状态?#
Jotai 是一个轻量级的状态管理库,专为 React 应用程序设计。它基于原子(atoms)和选择器(selectors)的概念,使状态管理变得简单和高效。Jotai 的核心思想是将状态分解为最小的、可组合的单元(原子),从而使得状态易于管理和跟踪。与 Redux 或 MobX 等其他状态管理库相比,Jotai 更加轻量级且易于学习。
使用 Jotai 和使用 Context API 相比,其优点在于更加简单、灵活和易于维护。以下是一些原因:
-
简单易用。
使用 Jotai 只需要创建原子(atom)并使用 React Hooks 即可进行状态管理。相对于 Context API,使用 Jotai 的代码更加简单易用。 -
高度灵活。
Jotai 允许你随意组合和复合不同的原子来创建更复杂的状态,从而使得状态管理更加灵活和可扩展。相对于 Context API,使用 Jotai 的灵活性更高。 -
更好的性能。
使用 Jotai 可以避免 Context API 中因为使用 Provider 和 Consumer 组件造成的无用渲染,从而提高应用的性能。Jotai 会自动优化组件的重新渲染,并且只在原子状态发生变化时才会更新相关组件。 -
更易于维护。
使用 Jotai 可以使得状态管理更加清晰、明确和易于维护。通过将状态分解为多个原子,每个原子只包含一个状态值,可以更好地控制状态的变化和维护应用的状态。
使用 Jotai 可以使得状态管理更加简单、灵活、易于维护,并且具有更好的性能表现。当然,使用 Context API 也可以进行状态管理,而且更加原生,但是在处理复杂状态时可能需要编写更多的代码,并且容易造成性能问题。因此,在选择状态管理库时,需要根据具体情况进行选择。
数据传递和处理#
1. 如何在 React 组件之间传递数据(props)?#
- 父组件向子组件传递数据
在父组件中使用子组件时,可以通过在子组件上添加属性来传递数据。例如:
function Parent() {
const data = {name: 'John', age: 30};
return <Child data={data} />;
}
function Child(props) {
return (
<div>
<p>Name: {props.data.name}</p>
<p>Age: {props.data.age}</p>
</div>
);
}
在这个例子中,父组件 Parent 向子组件 Child 传递了一个名为 data 的对象,子组件可以通过 props.data 来访问这个对象。
- 子组件向父组件传递数据
在子组件中,可以通过调用父组件传递的函数来向父组件传递数据。例如:
function Parent() {
function handleChildData(data) {
console.log(data);
}
return <Child onData={handleChildData} />;
}
function Child(props) {
function handleClick() {
props.onData('Hello, parent!');
}
return <button onClick={handleClick}>Click me</button>;
}
在这个例子中,子组件 Child 通过调用 props.onData 函数来向父组件传递数据。
- 兄弟组件之间传递数据
在兄弟组件之间传递数据可以通过在它们的共同父组件中定义状态,然后将状态作为 props 属性传递给它们。例如:
function Parent() {
const [data, setData] = useState('Hello, world!');
return (
<>
<Sibling1 data={data} />
<Sibling2 setData={setData} />
</>
);
}
function Sibling1(props) {
return <p>{props.data}</p>;
}
function Sibling2(props) {
function handleClick() {
props.setData('Hello, sibling 1!');
}
return <button onClick={handleClick}>Click me</button>;
}
在这个例子中,Sibling1 和 Sibling2 是兄弟组件,它们之间通过共同的父组件 Parent 中的状态 data 进行通信,Sibling1 通过 props.data 属性获取数据,Sibling2 通过 props.setData 函数来更新数据。
2. 什么是 React 中的 "lift state up"(状态提升)模式?为什么它对数据传递和处理很重要?#
"状态提升"(lift state up)是 React 中一种常见的模式,用于处理组件之间的数据传递和状态管理。这种模式的主要思想是将组件之间共享的状态提升到它们的共同父组件中进行管理,以便更好地管理和协调组件之间的数据流动。
通过将状态提升到共同的父组件中,可以将状态作为 props 传递给子组件,从而在组件之间共享数据。这可以使得组件之间的数据传递更加清晰和直观,避免了组件之间互相依赖和相互修改状态的问题。此外,这种模式也可以减少重复的状态管理代码,从而使代码更加简洁和易于维护。
"状态提升" 模式对于处理组件之间的数据传递和状态管理非常重要。在 React 中,组件之间的数据传递通常是通过 props 属性来实现的。当组件需要访问共享状态时,可以将这些状态提升到它们的共同父组件中进行管理,并将状态作为 props 属性传递给子组件。这种模式可以使得组件之间的数据传递更加清晰和直观,避免了组件之间互相依赖和相互修改状态的问题。
除此之外,"状态提升" 模式还可以使得代码更加可靠和可维护。通过将状态提升到共同的父组件中进行管理,可以减少重复的状态管理代码,并将状态逻辑封装在父组件中,从而使得代码更加简洁和易于维护。
3. 如何处理异步数据加载和更新(例如从 API 获取数据)?#
- 使用 useEffect Hook
可以使用 useEffect Hook 来处理异步数据加载和更新。在 useEffect 中,可以使用异步函数来获取数据,并使用 useState Hook 来保存数据和更新状态。例如:
import { useEffect, useState } from 'react';
function App() {
const [data, setData] = useState([]);
useEffect(() => {
async function fetchData() {
const response = await fetch('https://api.example.com/data');
const data = await response.json();
setData(data);
}
fetchData();
}, []);
return (
<ul>
{data.map((item) => (
<li key={item.id}>{item.title}</li>
))}
</ul>
);
}
在这个例子中,通过 useEffect Hook 来异步获取数据,并使用 useState Hook 来保存数据和更新状态。useEffect 的第二个参数为空数组,表示只在组件挂载时执行一次。
- 使用事件回调
可以在组件内部使用事件回调来处理异步数据加载和更新。例如:
import { useState } from 'react';
function App() {
const [data, setData] = useState([]);
async function fetchData() {
const response = await fetch('https://api.example.com/data');
const data = await response.json();
setData(data);
}
return (
<div>
<button onClick={fetchData}>Load data</button>
<ul>
{data.map((item) => (
<li key={item.id}>{item.title}</li>
))}
</ul>
</div>
);
}
在这个例子中,使用事件回调来处理异步数据加载和更新。点击按钮时,调用 fetchData 函数来重新获取数据,并将数据保存在状态中。
使用那种方式需要看具体的需求场景,正确区分 Event 与 Effect 是非常重要的,可以参考这篇文档:separating-events-from-effects
4. 什么是受控组件和非受控组件?它们在数据处理中的应用场景分别是什么?#
受控组件和非受控组件,这两个概念通常是针对表单元素(如输入框、选择框和单选按钮等)而言的。
然而,实际上这两个概念也可以扩展到非表单元素的组件。关键在于如何管理组件内部的状态,以及如何处理来自外部的数据。以下是一个简单的例子,说明如何将受控和非受控概念应用于非表单元素的组件:
受控组件(非表单元素):
import React from 'react';
function ControlledDiv({ content, onContentChange }) {
const handleClick = () => {
onContentChange('New Content');
};
return <div onClick={handleClick}>{content}</div>;
}
在这个例子中,ControlledDiv 组件接收一个 content 属性和一个 onContentChange 回调函数。当用户点击这个组件时,它会触发回调函数来更新外部传入的 content。这意味着组件内部的状态由外部控制,因此可以将其视为受控组件。
非受控组件(非表单元素):
import React, { useState } from 'react';
function UncontrolledDiv() {
const [content, setContent] = useState('Initial Content');
const handleClick = () => {
setContent('New Content');
};
return <div onClick={handleClick}>{content}</div>;
}
在这个例子中,UncontrolledDiv 组件内部维护了一个 content 状态。当用户点击这个组件时,它会直接更新内部的状态而不需要从外部获取数据。因此,这个组件可以被视为非受控组件。
总之,尽管受控组件和非受控组件的概念主要用于表单元素,但它们实际上可以扩展到非表单元素的组件,关键在于组件状态的管理和数据处理方式。
5. 如何使用 React 的 useCallback 和 useMemo Hooks 来优化数据处理和函数传递?#
useCallback 和 useMemo 是 React 的两个 Hooks,它们可以帮助优化数据处理和函数传递,避免不必要的组件重新渲染。以下是以 useMemo 为例
import { useMemo, memo, useState } from "react";
const ChildComponent = memo(function ChildComponent({ data }) {
console.log("Childcomponent render");
return (
<div>
<p>Name: {data.name}</p>
<p>Age: {data.age}</p>
</div>
);
});
function ParentComponent() {
const [num, setNum] = useState(0);
// 不要学习这个示例,没有性能问题时不要使用 useMemo useCallback
const data = useMemo(() => {
return { name: "John", age: 30 };
}, []);
return (
<>
<div>
num: {num}{" "}
<button onClick={() => setNum((_num) => _num + 1)}>increase</button>
</div>
<ChildComponent data={data} />
</>
);
}
export default ParentComponent;
在这个例子中,ParentComponent 使用 useMemo 包裹了一个 object,并将其作为 props 传递给 memo 包裹的 ChildComponent。由于 ChildComponent 是 memo 包裹的,只有当 data 发生变化时,ChildComponent 才会重新渲染。
当我们点击 increase 按钮时,虽然 ParentComponent 发生了 rerender,但是 data 使用 useMemo 包裹,data 的引用未改变,所以 ChildComponent 不会重新渲染。
::: tip
请注意 ChildComponent 必须是 React.memo 包裹的组件上述 useMemo 的优化才会生效。
这是因为当 ParentComponent rerender 时其子组件就会 rerender,不论其 props 是否发生了改变。只有当其子组件是 React.memo 组件时,React 才会使用 Object.is 比较 props 是否变更来决定是否跳过 rerender。
:::
6. 如何利用 React 的自定义 Hooks 来封装和复用数据处理逻辑?#
自定义 Hooks 是一种在函数组件中封装和复用状态和副作用逻辑的方法。自定义 Hooks 的命名通常以 use 开头。下面是一个简单的自定义 Hook 示例:
import React, { useState, useEffect } from 'react';
// 定义一个用于封装数据处理逻辑的自定义 Hook
function useDataHandling(data) {
const [processedData, setProcessedData] = useState(null);
useEffect(() => {
// 定义数据处理逻辑
function processData(data) {
// ... 数据处理过程 ...
return processedData;
}
// 处理数据并更新状态
setProcessedData(processData(data));
}, [data]);
// 返回处理后的数据
return processedData;
}
// 在函数组件中使用自定义 Hook
function MyComponent({ data }) {
const processedData = useDataHandling(data);
// ... 使用处理后的数据 ...
}
自定义 Hook 可以帮助让代码更加模块化和清晰。即使不考虑代码复用,将逻辑拆分到自定义 Hook 中仍然具有一定的优势:
- 关注点分离:自定义 Hook 可以将组件中的不同关注点(如状态管理、副作用处理、数据处理等)分离到不同的 Hook 中。这有助于让组件代码更加简洁,易于理解和维护。
- 逻辑解耦:将特定逻辑封装到一个自定义 Hook 中,可以降低组件之间的耦合程度,使组件更具灵活性。这样,当需求变化时,修改自定义 Hook 不会影响到其他组件。
- 易于测试:自定义 Hook 可以独立于组件进行测试。这意味着您可以针对特定的逻辑编写单元测试,而无需担心其他组件的影响。
- 更好的可读性:使用自定义 Hook 可以让组件代码更具描述性,因为 Hook 的名称往往能够直接反映其功能和作用。这有助于提高代码的可读性和可维护性。
因此,在实际开发中,即使某段代码不会被复用,将其拆分到自定义 Hook 中也是有好处的。在进行代码重构时,可以考虑将逻辑拆分到合适的自定义 Hook 中,以提高代码质量。